Sida mak apache spark Mlib?
Mlib Apache Spark MLlib mak funsiona hodi fornese enkuadramentu aprendizajen mákina distribuidu ne'ebé permite sientista no enjeñeiru sira dadus nian atu harii no hala'o modelu sira iha konjuntu dadus ne'ebé boot tebes ho efisiente. Prosesu hahú ho karregamentu no pré-prosesamentu dadus, dala barak hosi fonte dadus boot sira hanesan Hadoop Distributed File System (HDFS) ka arkivu estruturadu sira hanesan CSV, JSON, ka Parquet. Dadus sira hamoos, transforma, no konverte ba karakterístika numérika sira uza ferramenta sira hanesan enkoder, eskaladór, no montadór vetor sira. Bainhira dadus sira preparadu ona, MLlib uza algoritmu sira aprendizajen mákina nian ne'ebé bele eskala hanesan regresaun lojístika, ai-hun desizaun sira, regresaun lineár, ka agrupamentu K-means hodi treinu modelu sira iha paralelu iha agrupamentu ida nia laran. Etapa sira-ne'e dalabarak organiza iha pipeline ida, ne'ebé liga hamutuk etapa sira pré-prosesamentu, treinamentu, no predisaun nian iha fluxu serbisu ida ne'ebé bele repete. Depois de treinamentu, modelu bele halo predisaun ba dadus foun ho lalais tanba komputasaun mós distribui. MLlib mós inklui ferramenta sira ba avaliasaun modelu, validasaun kruzada, no ajustamentu hiperparámetru nian hodi hadi'a dezempeñu. Jeralmente, Spark MLlib permite aprendizajen mákina ne'ebé lalais, eskalavel, no konfiável iha dadus boot liuhosi kombinasaun prosesamentu dadus, enjeñaria karakterístika, treinamentu modelu, no avaliasaun iha enkuadramentu ida ne'ebé maka'as..
 Mlib
Mlib
Karakterístika Xave sira
1. Data Loading & Preprocessing
Apache Spark MLlib hahú ho importa dadus boot husi fonte sira seluk hanesan CSV, JSON, Parquet, baze dadus, ka Hadoop Distributed File System (HDFS). Dadus ne’e normalmenti susar no iha erru, tanba ne’e Spark halo limpeza no prepara — halakon valor lakon, korrije erru, no troka liafuan ba númeru. Dadus ne’e guarda iha DataFrame, ne’ebé fasil atu procesa iha Spark.
2. Feature Engineering
Depois dadus ne’e limpa, Spark troka ba feature (karakterístika númerika) atu bele uza iha modelu machine learning. Nee inklui: Normalizasaun no scaling númeru, troka liafuan ka kategoria ba númeru, redusa dimensaun ho teknik hanesan PCA. Etapa ida ne’e importante tanba feature di’ak bele fó modelu sai mais loos.
3. Model Training (Estimator)
Iha etapa ida ne’e, Spark uza algoritmu ML hanesan Logistic Regression, Decision Tree, ka K-Means atu treina modelu. Spark fahe dadus iha parte barak ba komputador barak iha cluster, treina paralelamente, no depois fó resultadu hamutuk. Nee halo prosesu treinamentu sai lalais liu.
4. Pipeline Structuret
MLlib uza pipeline, ne’ebé liga etapa sira hotu hamutuk — preprocessamentu, feature engineering, treinamentu no predisaun — iha fluxu automátiku ida. Nee ajuda atu organiza traballu ho di’ak no reutiliza prosesu ne’e ba dadus foun.
5. TensorFlow Serving and TensorFlow Model Optimization
TensorFlow inklui ferramenta sira hodi serve modelu aprendizajen mákina nian iha ambiente produsaun nian no optimiza sira ba inferénsia ne'ebé permite latência ne'ebé ki'ik liu no efisiénsia ne'ebé aas liu.
Arkitetura MLib
Arsitektura Apache Spark MLlib projetadu atu fasilita prosesu machine learning iha data boot, husi forma distribuída no automátika. Prosesu tuir husi input data, ne'ebe bele husi file CSV, JSON, database, sensor IoT, ka streaming real-time, ne’ebé prosesadu hanesan RDD ka DataFrame. Dados mentah sei tau ba transformasaun fitur, uza komponente hanesan StringIndexer, OneHotEncoder, VectorAssembler, no StandardScaler. Depoi, prosesu entra iha ML Pipeline, ne'ebe organiza sekensa ML, inklui Estimator, Transformer, no Evaluator. Modelu sei treina no testa uza algoritmu hanesan Linear Regression, Logistic Regression, K-Means, ka Random Forest, no depois deploy ba aplikasaun real-time ka batch.
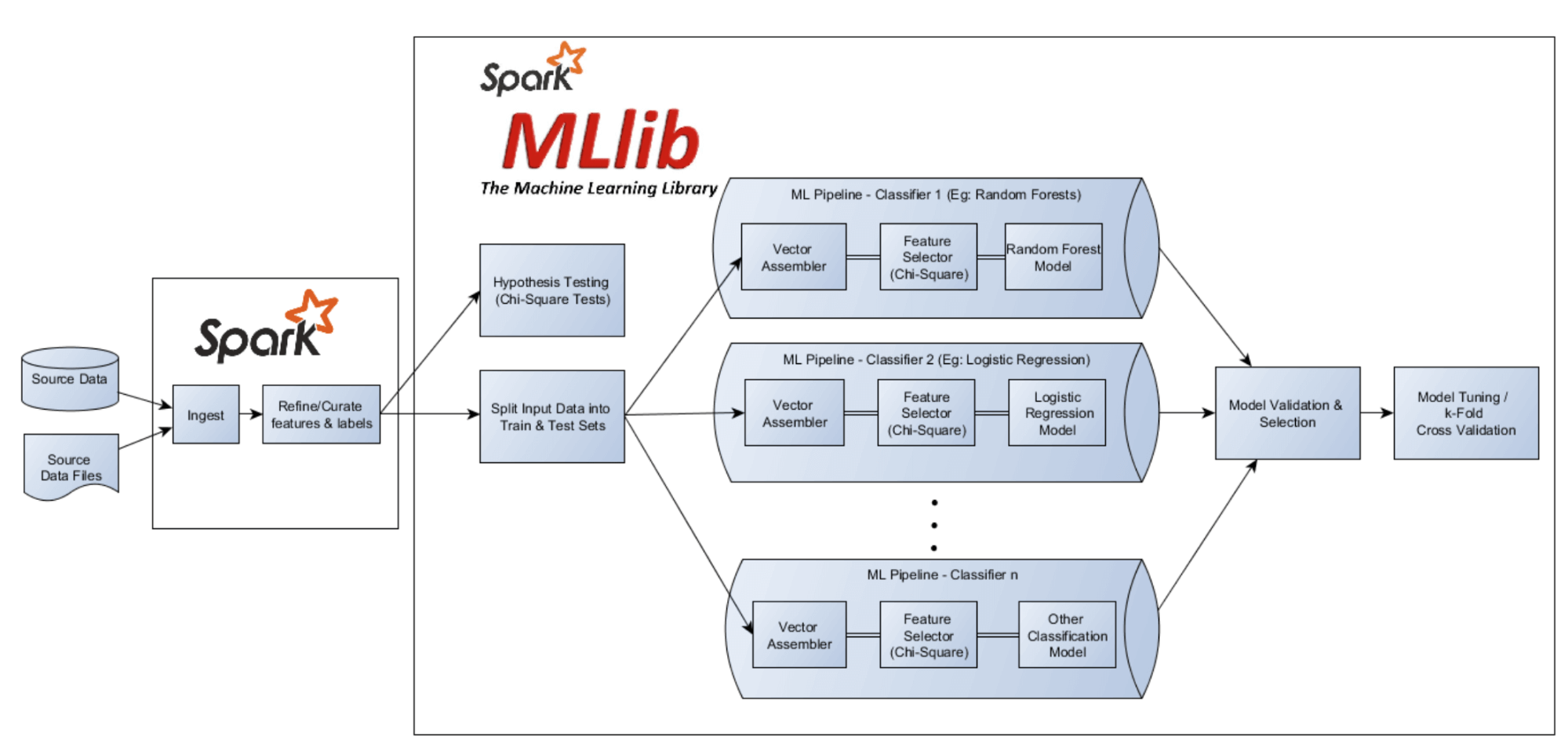 Gambar: Arsitektura MLlib
Gambar: Arsitektura MLlib
1. Input Data
Prosesu ML iha MLlib halao husi input data, ne'ebe bele tau husi fonte diferente hanesan file CSV, JSON, database, sensor IoT, ka streaming real-time. Data nee sei prosesadu hanesan RDD ka DataFrame hodi fasilita analize.
2. Feature Transformation
Data mentah sei tau ba transformasaun fitur, ne'ebe mak konverte data ba forma númeriku. Komponente importante hanesan StringIndexer, OneHotEncoder, VectorAssembler, no StandardScaler.
3. ML Pipeline
MLlib uza pipeline atu organiza prosesu ML iha sekensa sistemátiku. Pipeline mak inklui Estimator, Transformer, no Evaluator. Abordajen pipeline ajuda halo prosesu ML automatizadu, reproduzível, no efisiente.
4. Model Training & Evaluation
Iha fase nee, model sei treina iha data training no testa iha data testing. MLlib suporta algoritmu hanesan Linear Regression, Logistic Regression, K-Means, Random Forest, no Gradient Boosted Trees.
MLlib Workflow
Harii modelu aprendizajen mákina ida iha MLlib normalmente envolve etapa sira tuirmai:
Step 1: Data Collection
Iha etapa nee, data mak kolekta husi fonte sira ne’ebé diferente, hanesan file CSV, JSON, database, sensor IoT, ka streaming real-time. Data nee bele prosesadu hanesan RDD ka DataFrame atu bele compatible ho Spark MLlib.
Step 2: Data Preprocessing
Data mentah sei limpa, validasaun halo, no konverte ba format ne’ebé model ML bele kompriende. Komponente hanesan StringIndexer, OneHotEncoder, VectorAssembler, no StandardScaler uza hodi transforma data.
Step 3: Pipeline Building
Pipeline mak mekanismu automatizadu iha MLlib. Iha ne’e, prosesu ML define iha urutan: Transformer → Estimator → Evaluator.
Step 4: Model Training and Evaluation
Modelu sei treina uza data training, no depois testa ho data testing atu hetan metrika performa hanesan accuracy, precision, recall, ka RMSE.
Step 5: Model Deployment
Depois avaliasaun, modelu bele implementa ba aplikasaun nyata, hodi halo predisaun iha forma batch ka real-time.